We’ve already explained how we built and tested the system we used for our biggest crowdfunding round yet. Next, we’ll look at some of the tools we built to prepare for the main event! And we’ll share what went on in the pop-up control centre where our team made sure everyone could invest smoothly on the day.
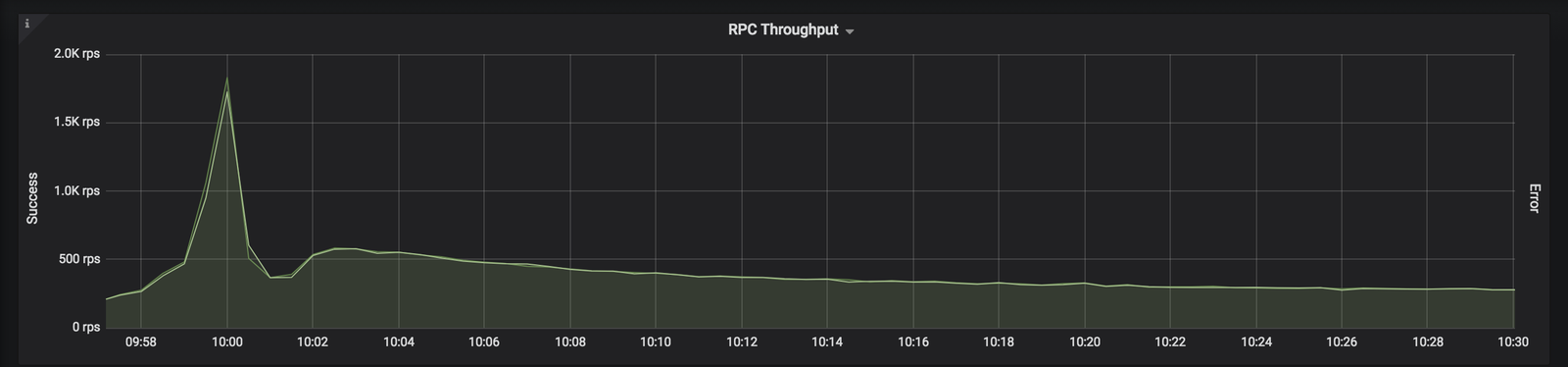
On a normal day we usually see around 150 requests per second to an individual API, and 1,500 requests per second to our system as a whole. But when we opened the investment round to new investors at 10am on Wednesday 5th December, we immediately started receiving 1,800 requests (calls for information or attempts to perform an action) per second to our investment APIs (application programming interfaces). Our system as a whole was receiving 4,300 requests per second.
This number of requests might not seem very high at first, but some requests can mean our servers have to do a lot of processing. Before crowdfunding, we spent time optimising what our servers do when you open your feed. And we also looked at updating our apps to reduce the amount of requests being made during crowdfunding. The result was that we raised about £18 million in just under three hours without any impact on our banking systems.
We made life easier by shedding load
We shedded load aggressively so that customers could still make payments and use the Monzo app as usual during crowdfunding. ‘Shedding load’ is the process of ignoring requests, and we need to do this when we get an abnormally large number of requests.
It’s useful as it reduces the amount of load your systems are under, and gives you time to fix any issues. This was especially important for crowdfunding because we predicted that a large amount of traffic would hit our APIs when crowdfunding started. And if anything went wrong, we didn’t know if our systems could recover while still receiving lots of traffic.
The high traffic we received only lasted for a short time, which meant we could shed load quite aggressively. We also made sure to test all the changes we implemented in our test environments. We did this to make sure that the apps were still usable and our customers could make payments regardless of what we turned off!
We updated the app to reduce load
To stop the spike in traffic from affecting the rest of the app, we decided to direct potential investors straight to the investment flow when traffic would be highest.
We displayed a crowdfunding splash screen during the first few minutes of the funding round. When anyone opened the app, they’d immediately see a screen asking if they wanted to invest, or to use Monzo as usual. If users wanted to invest, we’d take them directly to the investment flow, without having to load their transaction feed.
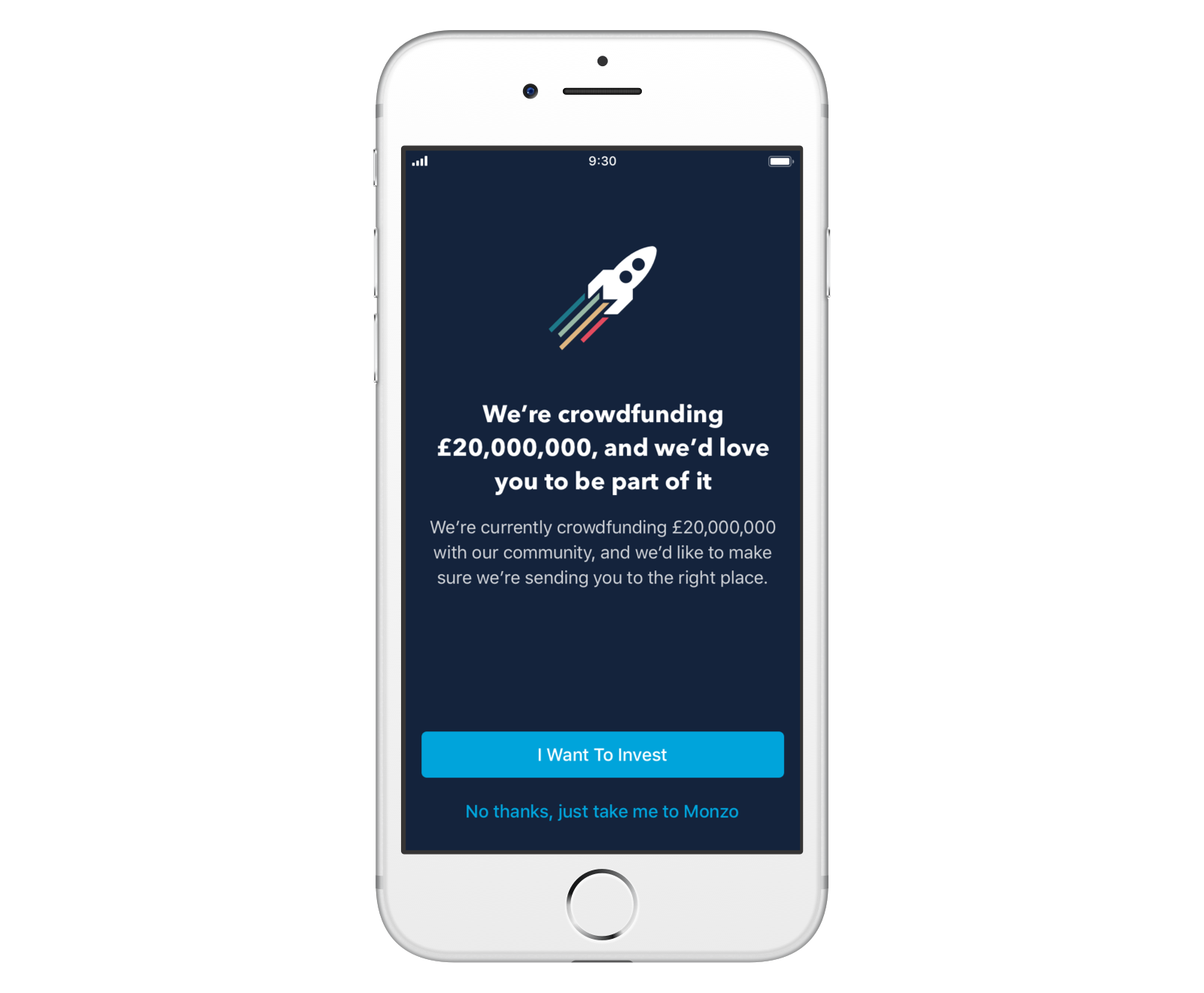
This helped us stop the peak in traffic from hitting the services which power our feed and transactions. We were able to prevent issues affecting our platform as a whole by reducing the load on our database and the services that power payments.
We used feature flags to turn off demanding features
For this crowdfunding round we used a set of new feature flags which can turn app features on and off. When these features were turned off the apps stopped making requests to the API, which is really useful for preventing extra load. For example, we added flags to turn off Contact Discovery, Profile Pictures, Summary, the Spending Graph and Feed. In the end we decided to turn off Contact Discovery and Profile Pictures as these are features which are demanding on our database but not critical to using the app.
We activated back-off headers to lower the frequency of requests
Back-off headers pretty much do what the name suggests. They help reduce load by lowering the frequency of requests made to our app. Basically, they tell requests to back off! Before we invited people to invest, we set different wait times for different areas of the app. We did this because some users might try to open and close their apps lots of times in anticipation of investment opening. This would would create extra unnecessary load for our platform and causes everything to slow down. Activating back-off headers helped us manage individual sets of requests, even if users were opening their app multiple times.
We rejected traffic from our backend/API
We added hard-coded response filters
To give us the ability to reduce the cost of handling each request, we added filters to our edge proxy. We use a system called an ‘edge proxy’ to receive and direct all incoming traffic to the relevant microservice. Our microservices are the systems which handle requests and then figure out how to respond to them. Ahead of crowdfunding, we added filters to our edge proxy that checked every request was heading to a destination we’d prepared for. When a filter detected one of these requests, we fired a hard-coded response right back, without any extra work needed.
We rejected a percentage of traffic
We had to prepare for the possibility that our servers couldn’t cope with the increase in traffic. Our solution was to prevent a percentage of traffic from reaching our apps. We decided we would block incoming GET requests – commands asking for data from a specified source. Doing things like freezing your card or making a payment would still be possible while GET requests are blocked.
We added a new header to all requests so we could start rejecting the GET ones. Each header included a random number between 1 and 100. We then used a firewall to reject these requests before they reached any of our internal services determined by the header. This is actually a pretty simple way of protecting yourself, but then sometimes the simplest solution is the best one. Thankfully we didn’t need to use it during crowdfunding, but it might be a useful tool for us in the future.
And we rejected specific API paths
We wanted the option to ignore traffic for certain parts of our API in the event that things went wrong. We don’t mind doing this because there are parts of our apps that are less important than others. For example, you should always be able to freeze your card or make a bank transfer. But it’s okay to reject API paths for less important features to in these circumstances. Examples of less important features are the APIs for checking if your contacts are Monzo users or getting profile pictures.
We tested our apps in advance of crowdfunding so we knew what was safe to temporarily turn off. We then grouped this list of APIs depending on how important the API was (including a group which would turn everything off!). Luckily, everything went well so we didn't need to use this feature.
We built the right tools to help us on the day
Managing a project like this can be tricky, especially with so many people involved. And our main concern was coping with the increase in traffic to our app. We used two tools to help us do this:
Runbooks – documents that explain how to deal with different situations, which prepared us for any issues we might face once we were live.
Dashboards – so we could monitor how things were going.
Having these tools ready ahead of time proved to be crucial. It helped us react to things quickly and reduce our stress levels on the day!

We prepared roles and runbooks
We started writing runbooks weeks before crowdfunding. Load testing helped us figure out what we should write runbooks for, because we could predict how things would perform on the day.
Things we wrote runbooks for:
How to configure the crowdfunding round ahead of time and make sure everything was ready.
How to pause the investment round if something unexpected happened that we could not recover from quickly.
How to enable the load shedding tools mentioned above.
How to recover from overloaded infrastructure.
These runbooks allowed us to react to things quickly, effectively and without too much thinking. Our on-call engineer team uses the same format for runbooks. Some of the runbooks we created for crowdfunding should also be really useful for dealing with any incidents in the future.
The next step was to come together a few days before crowdfunding started and walk through what would happen on the day. This included setting everything up for a pretend crowdfunding round and doing some test investments. We also pretended that things went wrong and followed certain steps to try and recover.
Next, we briefed the team. We assigned tasks to people so everyone knew what to do and who to go to if they needed something. And we nominated an Event Lead so the team could turn to someone for quick decisions and react to the activity on our dashboards.
We built dashboards to help us monitor in real-time
Being prepared beforehand was crucial to the success of crowdfunding, but so was how we monitored the activity as it happened. To keep things running smoothly, we needed the whole team to have access to information in near real-time.
We decided to use a monitoring system called Prometheus. It works by pulling data from thousands of sources, from system metrics like network throughput and CPU, to business level metrics like the number of crowdfunding investments made. We were able to monitor activity every five seconds by tweaking Prometheus’ reporting frequency. We tweaked the reporting frequency in Prometheus to update activity every five seconds, which was as close to real-time as we could get.
So we’d solved how to monitor things quickly. Great. Next we had to figure out what those things actually were. Which metrics should we display on our dashboard while investing was in full swing? We needed data that we could understand at a glance. We used Grafana ‘Single Stat’ for this. The Single Stat dashboard panels quickly communicated healthy (green) and unhealthy (red) data patterns which we could react to from our war room. We also displayed more detailed graphs for monitoring trends in more depth. Thankfully for us, all we saw during crowdfunding was a sea of green. But had anything gone wrong, we would have been ready to react quickly.
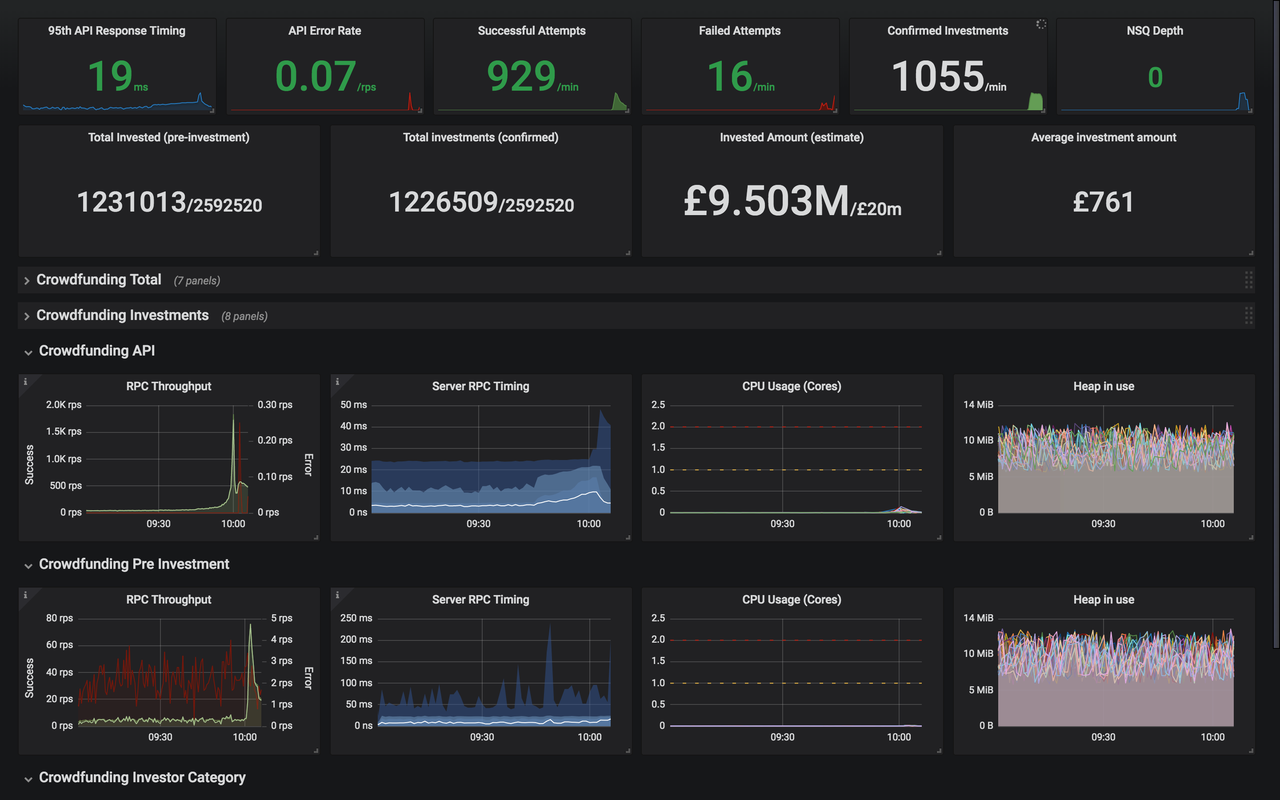
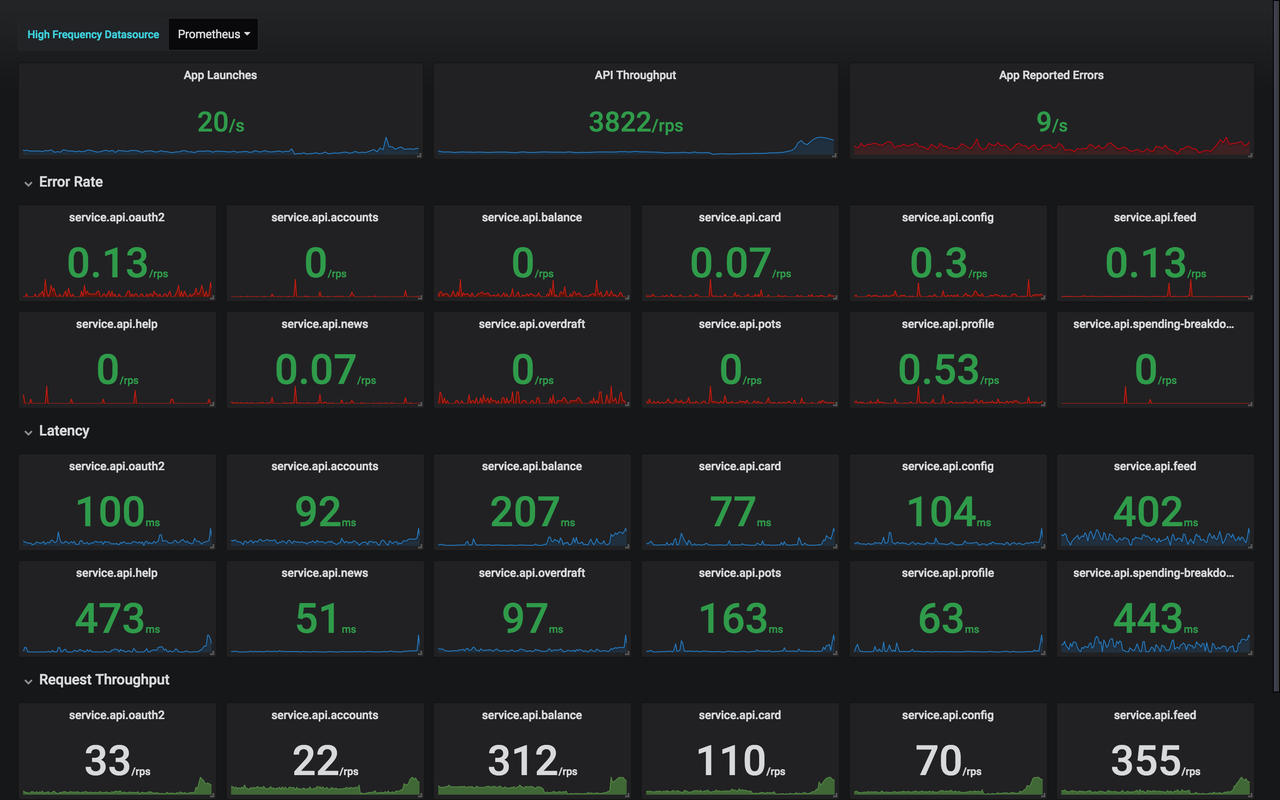
Things went well!
All in all, crowdfunding went really well. Our attempts to shed load worked and we had more than enough capacity to deal with the traffic that we saw over the three days of crowdfunding.
More importantly, investors told us that investing from the app was smooth and easy to do. A few of you said that some features (like Contacts) didn’t work as expected for a short time, and we’re looking into how we can avoid that in future. But the core parts of our app were unaffected. And that’s great news.
It was great to see the platform we’d built could handle this type of pressure, and we certainly learned a lot about how to prepare for future events like this one.
A huge thank you to everyone who invested. Your enthusiasm and excitement on social media kept us all going!